In a recent article, we saw how to implement a basic validation pipeline for text data. Once a machine learning model has been deployed its behavior must be monitored. The predictive performance is expected to degrade over time as the environment changes. This is known as concept drift, occurs when the distributions of the input features shift away from the distribution upon which the model was originally trained.
This time we come back to this and implement a more sophisticated approach to dectect and reduce the impact of concept drift. We will leverage a topic model based on Latent Dirichlet Allocation and estimate the likelihood of a new document under this model. This will give us a way to filter out documents.
Load the dataset
Like last time, we will use the Twitter Disaster Dataset from kaggle. Let’s load it and have a quick look.
import numpy as np
import pandas as pd
from pprint import pprint
import matplotlib.pyplot as plt
train = pd.read_csv("data/train.csv")
test = pd.read_csv("data/test.csv")
display(train.head())
| id | keyword | location | text | target | |
|---|---|---|---|---|---|
| 0 | 1 | NaN | NaN | Our Deeds are the Reason of this #earthquake M... | 1 |
| 1 | 4 | NaN | NaN | Forest fire near La Ronge Sask. Canada | 1 |
| 2 | 5 | NaN | NaN | All residents asked to 'shelter in place' are ... | 1 |
| 3 | 6 | NaN | NaN | 13,000 people receive #wildfires evacuation or... | 1 |
| 4 | 7 | NaN | NaN | Just got sent this photo from Ruby #Alaska as ... | 1 |
Build a topic model
To understand the distribution of our data, we build a so called topic model with the help of a Latent Dirichlet Allocation model. This is basically giving us a distribution of latent topics over our documents.
import warnings
warnings.simplefilter("ignore", DeprecationWarning)
warnings.simplefilter("ignore", FutureWarning)
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
# Initialise the count vectorizer with the English stop words
count_vectorizer = CountVectorizer(
stop_words='english',
ngram_range=(1,1),
max_df=0.9,
min_df=2,
max_features=10000,
binary=False
)
# Fit and transform the texts
count_data = count_vectorizer.fit_transform(train.text)
lda = LatentDirichletAllocation(
n_components=10,
doc_topic_prior=None, #defaults to 1/n_components; called alpha
n_jobs=-1,
max_iter=50,
random_state=2020
)
lda.fit(count_data)
LatentDirichletAllocation(batch_size=128, doc_topic_prior=None,
evaluate_every=-1, learning_decay=0.7,
learning_method='batch', learning_offset=10.0,
max_doc_update_iter=100, max_iter=50,
mean_change_tol=0.001, n_components=10, n_jobs=-1,
perp_tol=0.1, random_state=2020,
topic_word_prior=None, total_samples=1000000.0,
verbose=0)
doc_vectors = lda.transform(count_data)
Calculate the likelihood of the documents
Given the topic model, we can talk about the likelihood of a document give our corpus topic distribution. Now we calculate the likelihood of the documents under the topic model. Then this enables us to drop or flag unlikely documents.
log_likelihoods = [lda.score(d) for d in count_data]
train["log_likelihood"] = log_likelihoods
plt.hist(train["log_likelihood"], bins=100);
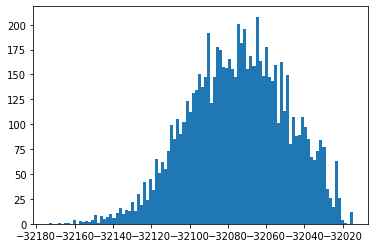
Here we can pick a reasonable threshold to invalidate documents. We just pick $-32140$ here, more sophisticated approaches can be used to determine a threshold.
Let’s look at some low probability examples.
for text in train[train.log_likelihood < -32140].sample(5).text.tolist():
print(text)
print()
@O_Magazine satan's daughter shadow warrior in 50ft women aka transgender mode ps nyc is about to fold extra extra center of bioterrorism
USGS EQ: M 1.9 - 5km S of Volcano Hawaii: Time2015-08-06 01:04:01 UTC2015-08-05 15:04:01 -10:00 a... http://t.co/3rrGHT4ewp #EarthQuake
Rare insight into #terror and How to fight it http://t.co/t6OBVWaPhW #Cameroon #USA #Whitehouse #ES #FR #Nigeria #UK #Africa #DE #CA #AU #JP
ETP Bengal floods: CM Mamata Banerjee blames DVC BJP claims state failed to use relief funds: Even as flood w... http://t.co/hsZjaFxrvi
#USGS M 1.2 - 23km S of Twentynine Palms California: Time2015-08-05 23:54:09 UTC2015-08-05 16:54:09 -07:0... http://t.co/kF0QYBKZOL #SM
… and some probable ones
for text in train[train.log_likelihood > -32060].sample(5).text.tolist():
print(text)
print()
@MythGriy they can't detonate unless they touch the ground
@spinningbot Are you another Stand-user? If you are I will have to detonate you with my Killer Queen.
MY FAVS I'M SCREAMING SO FUCKING LOUD http://t.co/cP7c1cH0ZU
http://t.co/qr3YPEkfOe
Seems they declared war against government..
Reddit Will Now Quarantine Offensive Content http://t.co/8S0mTwRumQ #Technology #technews #puledo_tech_update
How would a random sentence from the new york times score?
text = """
Grab a hyperlocal bakery loaf and a copy of the kids’
newspaper, and we candiscuss over stoop cocktails.
"""
test_count_data = count_vectorizer.transform([text])
test_log_likelihood = lda.score(count_data)
print(test_log_likelihood)
-490373.43411015195
Wow, this is really unlikely! So it looks like our approach is going in the right direction.
Put everything together
Now we put it all together and build a validator with marshmallow.
from marshmallow import Schema, fields, validate, ValidationError
from typing import Callable
def build_topic_distribution_validator(vectorizer: CountVectorizer,
lda: LatentDirichletAllocation,
likelihood_threshold: int
) -> Callable[[str], None]:
"""Factory function to generate a topic distribution validator."""
# check if vectorizer and LDA are fitted
assert len(vectorizer.vocabulary_) > 0
assert lda.components_ is not None
def validate_topic_distribution(text: str):
"""
Validate new text based on the likelihood
under the given topic model.
Raises:
ValidationError
"""
# Prepare the input text as a bag of words representation.
count_data = count_vectorizer.transform([text])
# Calculate the log likelihood of the text under the topic model.
log_likelihood = lda.score(count_data)
# raise a ValidationError if the likelihood is to low.
if log_likelihood < likelihood_threshold:
raise ValidationError("Low log_likelihood: {}"
.format(log_likelihood))
return validate_topic_distribution
class TweetSchema(Schema):
id = fields.Integer(required=True)
text = fields.String(validate=[
build_topic_distribution_validator(
vectorizer=count_vectorizer,
lda=lda,
likelihood_threshold=-32140
)
])
Let’s try it!
Now we can try to validate new text with our defined schema.
test_data = test[["id", "text"]].to_dict(orient="records")
try:
print("## Received {} rows.\n".format(len(test_data)))
result = TweetSchema(many=True).load(test_data)
except ValidationError as err:
print("Error log:")
pprint(err.messages)
result = [d for i, d in enumerate(err.valid_data)
if i not in err.messages.keys()]
finally:
print("\n## Received {} valid rows, removed {} rows"
.format(len(result), len(test_data) - len(result)))
## Received 3263 rows.
Error log:
{272: {'text': ['Low log_likelihood: -32145.76438466925']},
279: {'text': ['Low log_likelihood: -32145.76438466925']},
283: {'text': ['Low log_likelihood: -32145.76438466925']},
377: {'text': ['Low log_likelihood: -32140.326469146872']},
443: {'text': ['Low log_likelihood: -32140.487821195242']},
492: {'text': ['Low log_likelihood: -32148.10142377125']},
622: {'text': ['Low log_likelihood: -32146.209645043953']},
1321: {'text': ['Low log_likelihood: -32141.97497690581']},
1328: {'text': ['Low log_likelihood: -32145.879121159487']},
1653: {'text': ['Low log_likelihood: -32144.34863603786']},
1655: {'text': ['Low log_likelihood: -32141.34361056529']},
1656: {'text': ['Low log_likelihood: -32148.34468112231']},
1657: {'text': ['Low log_likelihood: -32141.34361056529']},
1659: {'text': ['Low log_likelihood: -32141.34361056529']},
1660: {'text': ['Low log_likelihood: -32148.34468112231']},
1663: {'text': ['Low log_likelihood: -32148.34468112231']},
1716: {'text': ['Low log_likelihood: -32145.31897649511']},
1717: {'text': ['Low log_likelihood: -32146.492450078884']},
1720: {'text': ['Low log_likelihood: -32141.76214207046']},
1723: {'text': ['Low log_likelihood: -32147.715664751166']},
2262: {'text': ['Low log_likelihood: -32141.276445150634']},
2901: {'text': ['Low log_likelihood: -32163.679554207767']},
3091: {'text': ['Low log_likelihood: -32154.466414031518']},
3093: {'text': ['Low log_likelihood: -32144.353229998644']},
3148: {'text': ['Low log_likelihood: -32140.636353213038']},
3153: {'text': ['Low log_likelihood: -32157.420986639157']}}
## Received 3237 valid rows, removed 26 rows
This looks nice and does exactly what we want.
Summary
We saw how to build sophisticated validators with marshmallow to prevent or detect concept drift or input degradation. To achieve this we leveraged a probabilistic topic model called Latent Dirichlet Allocation and flagged docuemnts with a low likelihood under this model.
Give it a try in your NLP pipelines and let me know how it works for you.
