This time, I’m going to talk about how to approach general NLP problems. But we’re not going to look at the standard tips which are tosed around on the internet, for example on platforms like kaggle. Instead we will focus on how to approach NLP problems in the real world. A lot of the things mentioned here do also apply to machine learning projects in general. But here we will look at everything from the perspective of natural language processing and some of the problems that arise there.
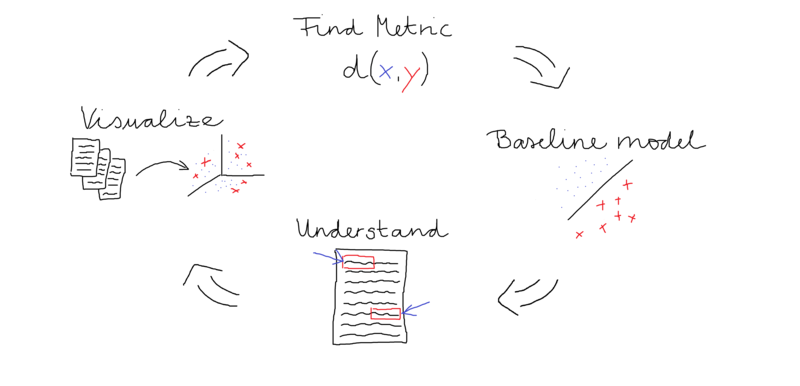
TL;DR
Precaution
We will focus mostly on common NLP problems like classification, sequence tagging and extracting certain kinds of information from a supvervised point of view. Nevertheless, some of the things mentioned here also apply to some unsupervised problem settings.
Understand what you need to measure
An import and challenging step in every real-world machine learning project is figuring out how to properly measure performance. This should really be the first thing after you figured out what data to use and how to get this data. You should think carefully about your objectives and settle for a metric you compare all models with. In many cases it will be hard to measure exactly what your business objective is, but try to be as close as possible. If you craft a specific metric like a weighted or asymmetic metric function, I would also recommend to include a simple metric you have some intuituion about. This helps to spot issues with potentially unreasonable values earlier.
Have a baseline
The most important thing is to have a simple, easily reproducible baseline.
If you are dealing with a text classification problem, I would recommend to use a simple bag of words model with a logistic regression classifier. If it makes sense, try to break your problem down to a simple classification problem. If you are dealing with a sequence tagging problem, I would say the easiest way to get a baseline right now is to use a standard one-layer LSTM model from keras (or pytorch). I would recommend to not spend a lot of time of hyperparameter selection. But of course make the baseline perform reasonable. For example, in a balanced binary classificaion problem, your baseline should perform better than random. If you cannot get the baseline to work this might indicate that your problem is hard or impossible to solve in the given setup. Make the baseline easily runable and make sure you can re-run it later when you did some feature engineering and probabily modified your objective. People often move to more complex models and change data, features and objectives in the meantime. This might influence the performance, but maybe the baseline would benefit in the same way. The baseline should help you to get an understanding about what helps for the task and what is not so helpful. So make sure your baseline runs are comparable to more complex models you build later.
Understand your data and the model
Text data can be hard to understand and whole branches of unsupervised machine learning and other technics are working on this problem. In our situation, we need to make sure, we understand the structure of our dataset in view of our classification problem. So I would recommend to look at the data through the lense of our baseline.
The questions we need to answer are:
- Is the preprocessing and tokenization appropriate?
- What kind of signal is the model picking up and does it make sense?
- Is there leakage, spurious signal or similiar?
- How do the errors of the model look like? Do they make sense? Are they probably labeling issues or inconsistencies?
Now is the time to address these issus if you find some. Don’t jump to more complex models before you ruled out leakage or spurious signal and fixed potential label issues. Maybe you also need to change the preprocessing steps or the tokenization procedure. Simple models are more suited for inspections, so here the simple baseline work in your favour. Other useful tools include LIME and visualization technics we discuss in the next part.
Use visualizations heavily
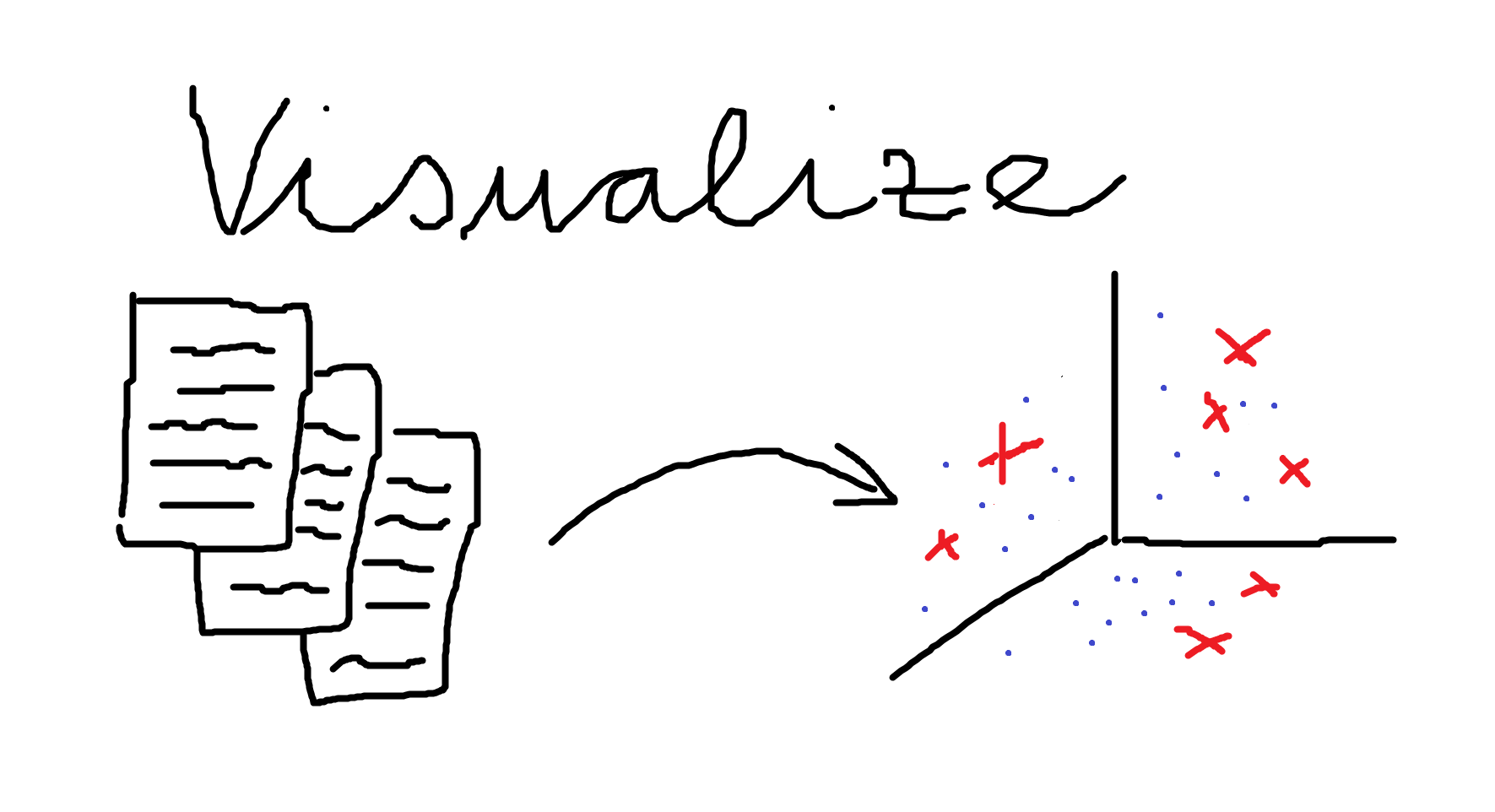
A good visualizations can help you to gasp complex relationships in your dataset and model fast and easy. One approach can be, to project the data representations to a 3D or 2D space and see how and if they cluster there. This can be run a PCA on your bag of word vectors, use UMAP on the embeddings for some named entity tagging task learned by an LSTM or something completly different that makes sense.
But be careful, humans are very good at rationalizing things and making up patterns where there are none. Still visual inspection can guide the NLP development process.
Iterate!
Go back to the first step and redo and improve!
If you need to, increase the complexity of your model now. But make sure your new model stays comparable to your baseline and you actually compare both models.
Summary
- Pick an appropriate measure that reflects your business needs as close as possible.
- Build a simple and reproductible baseline pipeline and model.
- Use the baseline model to understand the signal in your data and what potential issues are.
- Leverage visualizations to understand the model and data
- Iterate!
