Today we want to build a model, that can identify ingredients in cooking recipes. I use the “German Recipes Dataset”, I recently published on kaggle. We have more than 12000 German recipes and their ingredients list. First we will generate labels for every word in the recipe, if it is an ingredient or not. Then we use a sequence-to-sequence neural network to tag every word. Then we pseudo-label the training set and update the model with the new labels.
import numpy as np
import pandas as pd
Load the recipes
df = pd.read_json("../input/recipes.json")
df.Instructions[2]
'Die Kirschen abtropfen lassen, dabei den Saft auffangen. Das Puddingpulver mit dem Vanillezucker mischen und mit 6 EL Saft glatt rühren. Den übrigen Kirschsaft aufkochen und vom Herd nehmen. Das angerührte Puddingpulver einrühren und unter Rühren ca. eine Minute köcheln. Die Kirschen unter den angedickten Saft geben. Milch, 40 g Zucker, Vanillemark und Butter aufkochen. Den Topf vom Herd ziehen und den Grieß unter Rühren einstreuen. Unter Rühren einmal aufkochen lassen und zugedeckt ca. fünf Minuten quellen lassen.In der Zeit das Ei trennen. Das Eiweiß mit einer Prise Salz steif schlagen und dabei die restlichen 20 g Zucker einrieseln lassen. Das Eigelb unter den Brei rühren und dann das Eiweiß unterheben.Den Grießbrei mit dem Kompott servieren.'
We put some recipes aside for later evaluation.
eval_df = df[11000:]
eval_df.shape
(1190, 8)
df = df[:11000]
df.shape
(11000, 8)
Tokenize the texts with spacy
!python -m spacy download de_core_news_sm
Collecting de_core_news_sm==2.0.0 from https://github.com/explosion/spacy-models/releases/download/de_core_news_sm-2.0.0/de_core_news_sm-2.0.0.tar.gz#egg=de_core_news_sm==2.0.0
[?25l Downloading https://github.com/explosion/spacy-models/releases/download/de_core_news_sm-2.0.0/de_core_news_sm-2.0.0.tar.gz (38.2MB)
[K 100% |████████████████████████████████| 38.2MB 85.4MB/s ta 0:00:011 19% |██████▏ | 7.3MB 87.8MB/s eta 0:00:01
[?25hInstalling collected packages: de-core-news-sm
Running setup.py install for de-core-news-sm ... [?25ldone
[?25hSuccessfully installed de-core-news-sm-2.0.0
[93m Linking successful[0m
/opt/conda/lib/python3.6/site-packages/de_core_news_sm -->
/opt/conda/lib/python3.6/site-packages/spacy/data/de_core_news_sm
You can now load the model via spacy.load('de_core_news_sm')
import spacy
nlp = spacy.load('de_core_news_sm', disable=['parser', 'tagger', 'ner'])
We run the spacy tokenizer on all instructions.
tokenized = [nlp(t) for t in df.Instructions.values]
And now we build a vocabulary of known tokens.
vocab = {"<UNK>": 1, "<PAD>": 0}
for txt in tokenized:
for token in txt:
if token.text not in vocab.keys():
vocab[token.text] = len(vocab)
print("Number of unique tokens: {}".format(len(vocab)))
Number of unique tokens: 17687
Create the labels
What is missing now, are the labels. We need to know where in the text are ingredients. We will try to bootstrap this information from the provided ingredients list.
ingredients = df.Ingredients
ingredients[0]
['600 g Hackfleisch, halb und halb',
'800 g Sauerkraut',
'200 g Wurst, geräucherte (Csabai Kolbász)',
'150 g Speck, durchwachsener, geräucherter',
'100 g Reis',
'1 m.-große Zwiebel(n)',
'1 Zehe/n Knoblauch',
'2 Becher Schmand',
'1/2TL Kümmel, ganzer',
'2 Lorbeerblätter',
'Salz und Pfeffer',
'4 Ei(er) (bei Bedarf)',
'Paprikapulver',
'etwas Wasser',
'Öl']
We first clean the ingredients lists from stopwords, numbers and other stuff.
def _filter(token):
if len(token) < 2:
return False
if token.is_stop:
return False
if token.text[0].islower():
return False
if token.is_digit:
return False
if token.like_num:
return False
return True
def _clean(text):
text = text.replace("(", "")
text = text.split("/")[0]
return text
clean = [_clean(t.text) for i in ingredients[214] for t in nlp(i) if _filter(t) and len(_clean(t.text)) >= 2]
clean
['Rosenkohl',
'Schalotten',
'Hühnerbrühe',
'Milch',
'EL',
'Crème',
'Speck',
'Kartoffelgnocchi']
def get_labels(ingredients, tokenized_instructions):
labels = []
for ing, ti in zip(ingredients, tokenized_instructions):
l_i = []
ci = [_clean(t.text) for i in ing for t in nlp(i) if _filter(t) and len(_clean(t.text)) >= 2]
label = []
for token in ti:
l_i.append(any((c == token.text or c == token.text[:-1] or c[:-1] == token.text) for c in ci))
labels.append(l_i)
return labels
labels = get_labels(ingredients, tokenized)
set([t.text for t, l in zip(tokenized[214], labels[214]) if l])
{'Crème', 'Hühnerbrühe', 'Milch', 'Rosenkohl', 'Schalotten', 'Speck'}
Modelling with a LSTM network
First we have to look at the length of our recipes, to determine the length we want to pad our inputs for the network to.
import matplotlib.pyplot as plt
%matplotlib inline
plt.hist([len([t for t in tokens]) for tokens in tokenized], bins=20);
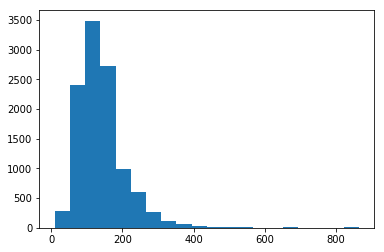
We picked a maximum length of 400 tokens.
MAX_LEN = 400
Prepare the sequences by padding
Now we pad the sequences and map the words to integers.
from keras.preprocessing.sequence import pad_sequences
def prepare_sequences(texts, max_len, vocab={"<UNK>": 1, "<PAD>": 0}):
X = [[vocab.get(w.text, vocab["<UNK>"]) for w in s] for s in texts]
return pad_sequences(maxlen=max_len, sequences=X, padding="post", value=vocab["<PAD>"])
Using TensorFlow backend.
X_seq = prepare_sequences(tokenized, max_len=MAX_LEN, vocab=vocab)
X_seq[1]
array([192, 193, 194, 183, 195, 196, 128, 197, 9, 198, 199, 200, 201,
202, 203, 60, 204, 205, 9, 13, 206, 15, 23, 98, 207, 208,
51, 209, 68, 202, 203, 25, 6, 195, 125, 202, 210, 211, 212,
33, 45, 213, 214, 100, 196, 13, 215, 216, 217, 33, 9, 68,
218, 219, 213, 169, 35, 82, 100, 220, 221, 202, 6, 222, 45,
223, 48, 224, 33, 67, 225, 100, 226, 6, 227, 228, 229, 130,
45, 92, 85, 230, 211, 231, 6, 232, 233, 234, 235, 145, 157,
236, 9, 237, 238, 104, 239, 210, 240, 157, 241, 54, 6, 109,
242, 243, 244, 245, 246, 187, 247, 6, 248, 183, 249, 250, 33,
129, 13, 251, 252, 101, 253, 33, 254, 9, 31, 255, 40, 172,
6, 2, 256, 257, 177, 258, 259, 260, 33, 42, 261, 262, 263,
131, 264, 265, 266, 33, 267, 74, 268, 269, 68, 270, 6, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int32)
y_seq = []
for l in labels:
y_i = []
for i in range(MAX_LEN):
try:
y_i.append(float(l[i]))
except:
y_i.append(0.0)
y_seq.append(np.array(y_i))
y_seq = np.array(y_seq)
y_seq = y_seq.reshape(y_seq.shape[0], y_seq.shape[1], 1)
Setup the network
Now we can start to setup the model.
import tensorflow as tf
from tensorflow.keras import layers
print(tf.VERSION)
print(tf.keras.__version__)
1.12.0
2.1.6-tf
We build a simple 2-layer LSTM-based sequence tagger with tensorflow.keras.
model = tf.keras.Sequential()
model.add(layers.Embedding(input_dim=len(vocab), mask_zero=True, output_dim=50))
model.add(layers.SpatialDropout1D(0.2))
model.add(layers.Bidirectional(layers.LSTM(units=64, return_sequences=True)))
model.add(layers.SpatialDropout1D(0.2))
model.add(layers.Bidirectional(layers.LSTM(units=64, return_sequences=True)))
model.add(layers.TimeDistributed(layers.Dense(1, activation='sigmoid')))
model.compile(optimizer=tf.train.AdamOptimizer(0.001),
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 50) 884350
_________________________________________________________________
spatial_dropout1d (SpatialDr (None, None, 50) 0
_________________________________________________________________
bidirectional (Bidirectional (None, None, 128) 58880
_________________________________________________________________
spatial_dropout1d_1 (Spatial (None, None, 128) 0
_________________________________________________________________
bidirectional_1 (Bidirection (None, None, 128) 98816
_________________________________________________________________
time_distributed (TimeDistri (None, None, 1) 129
=================================================================
Total params: 1,042,175
Trainable params: 1,042,175
Non-trainable params: 0
_________________________________________________________________
And now we fit it.
history = model.fit(X_seq, y_seq, epochs=10, batch_size=256, validation_split=0.1)
Train on 9900 samples, validate on 1100 samples
Epoch 1/10
9900/9900 [==============================] - 131s 13ms/step - loss: 0.3855 - acc: 0.9019 - val_loss: 0.2982 - val_acc: 0.9108
Epoch 2/10
9900/9900 [==============================] - 127s 13ms/step - loss: 0.2846 - acc: 0.9105 - val_loss: 0.2620 - val_acc: 0.9108
Epoch 3/10
9900/9900 [==============================] - 127s 13ms/step - loss: 0.2379 - acc: 0.9112 - val_loss: 0.1950 - val_acc: 0.9160
Epoch 4/10
9900/9900 [==============================] - 128s 13ms/step - loss: 0.1214 - acc: 0.9528 - val_loss: 0.0729 - val_acc: 0.9746
Epoch 5/10
9900/9900 [==============================] - 130s 13ms/step - loss: 0.0663 - acc: 0.9757 - val_loss: 0.0668 - val_acc: 0.9763
Epoch 6/10
9900/9900 [==============================] - 128s 13ms/step - loss: 0.0616 - acc: 0.9774 - val_loss: 0.0645 - val_acc: 0.9774
Epoch 7/10
9900/9900 [==============================] - 128s 13ms/step - loss: 0.0590 - acc: 0.9785 - val_loss: 0.0625 - val_acc: 0.9782
Epoch 8/10
9900/9900 [==============================] - 126s 13ms/step - loss: 0.0570 - acc: 0.9794 - val_loss: 0.0608 - val_acc: 0.9789
Epoch 9/10
9900/9900 [==============================] - 127s 13ms/step - loss: 0.0545 - acc: 0.9806 - val_loss: 0.0595 - val_acc: 0.9794
Epoch 10/10
9900/9900 [==============================] - 126s 13ms/step - loss: 0.0521 - acc: 0.9815 - val_loss: 0.0564 - val_acc: 0.9808
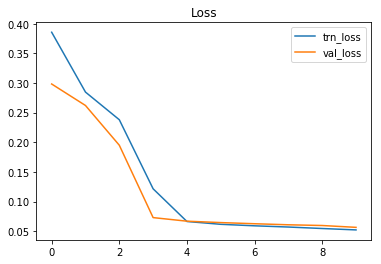
plt.plot(history.history["loss"], label="trn_loss");
plt.plot(history.history["val_loss"], label="val_loss");
plt.legend();
plt.title("Loss");
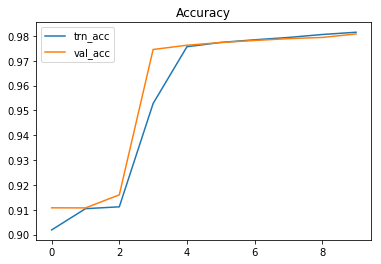
plt.plot(history.history["acc"], label="trn_acc");
plt.plot(history.history["val_acc"], label="val_acc");
plt.legend();
plt.title("Accuracy");
Analyse the predictions of the model
Now that the model is trained, we can look at some predictions on the training set.
y_pred = model.predict(X_seq, verbose=1, batch_size=1024)
11000/11000 [==============================] - 10s 945us/step
i = 3343
pred_i = y_pred[i] > 0.05
tokenized[i]
Kohlrabi schälen, waschen und in Stifte schneiden. Brühe und Milch ankochen, Kohlrabi dazugeben, aufkochen lassen und 10 Minuten kochen. Dann herausnehmen und abtropfen lassen, die Brühe aufheben.Butter erhitzen, das Mehl darin anschwitzen, mit Kohlrabibrühe ablöschen und aufkochen lassen. Mit den Gewürzen abschmecken. Kohlrabi wieder dazugeben.Hähnchenbrust schnetzeln, kräftig anbraten und würzen. Das Fleisch in eine Auflaufform geben, die Speckwürfel darüber verteilen. Mit Käse bestreuen. Nun das Gemüse darüber schichten und alles bei 180 °C ca. 25 Minuten überbacken.Tipp:Man kann auch gut gekochte, in Würfel geschnittene Kartoffeln unter die Kohlrabi mischen. Ebenso kann man auch Kohlrabi und Möhren für den Auflauf nehmen. Schmeckt auch sehr lecker!
ingreds = [t.text for t, p in zip(tokenized[i], pred_i) if p]
print(set(ingreds))
{'Milch', 'Kartoffeln', 'Möhren', 'Kohlrabi', 'Butter', 'Gemüse', 'Brühe', 'Käse', 'Speckwürfel', 'Mehl'}
ingreds = [t.text for t, p in zip(tokenized[i], y_seq[i]) if p]
set(ingreds)
{'Butter', 'Kohlrabi', 'Käse', 'Mehl', 'Milch'}
ingredients[i]
['500 g Kohlrabi',
'1/4Liter Hühnerbrühe',
'1/4Liter Milch',
'1 EL Butter',
'30 g Mehl',
'300 g Hähnchenbrustfilet(s)',
'Salz und Pfeffer',
'Muskat',
'50 g Käse, gerieben',
'50 g Speck, gewürfelt']
This looks very good! Our model seems to be able to identify the ingredients better than our training labels. So we now use the produced labels for fine-tuning the network.
new_labels = []
for pred_i, ti in zip(y_pred, tokenized):
l_i = []
ci = [t.text for t, p in zip(tokenized[i], pred_i > 0.05) if p]
label = []
for token in ti:
l_i.append(any((c == token.text or c == token.text[:-1] or c[:-1] == token.text) for c in ci))
new_labels.append(l_i)
y_seq_new = []
for l in new_labels:
y_i = []
for i in range(MAX_LEN):
try:
y_i.append(float(l[i]))
except:
y_i.append(0.0)
y_seq_new.append(np.array(y_i))
y_seq_new = np.array(y_seq_new)
y_seq_new = y_seq.reshape(y_seq_new.shape[0], y_seq_new.shape[1], 1)
We fit the network again for one epoch with the new labels.
history = model.fit(X_seq, y_seq_new, epochs=1, batch_size=256, validation_split=0.1)
Train on 9900 samples, validate on 1100 samples
Epoch 1/1
9900/9900 [==============================] - 127s 13ms/step - loss: 0.0479 - acc: 0.9834 - val_loss: 0.0533 - val_acc: 0.9824
Look at test data
Now we can look at the test data we put aside in the beginning.
eval_ingredients = eval_df.Ingredients.values
eval_tokenized = [nlp(t) for t in eval_df.Instructions.values]
X_seq_test = prepare_sequences(eval_tokenized, max_len=MAX_LEN, vocab=vocab)
y_pred_test = model.predict(X_seq_test, verbose=1, batch_size=1024)
1190/1190 [==============================] - 2s 2ms/step
i = 893
pred_i = y_pred_test[i] > 0.05
print(eval_tokenized[i])
print()
print(eval_ingredients[i])
print()
ingreds = [t.text for t, p in zip(eval_tokenized[i], pred_i) if p]
print(set(ingreds))
Den Quark durch ein Sieb in eine tiefe Schüssel streichen.Das Mehl, den Zucker, Salz, Vanillezucker und das rohe Ei/er gut verrühren.Diese Masse auf einem mit Mehl bestreuten Backbrett zu einer dicken Wurst rollen und in 10 gleichgroße Scheiben schneiden. In heißer Butter von beiden Seiten goldbraun braten.Die fertigen Tworoshniki werden mit Puderzucker bestreut oder warm mit saurer Sahne oder Obstsirup zu Tisch gebracht.
['500 g Quark, sehr trockenen', '80 g Mehl', '2 EL Zucker', '1 Pck. Vanillezucker', 'Salz', '1 Ei(er), evt. 2', '4 EL Butter oder Margarine', 'Puderzucker', '125 ml Sirup (Obstsirup) oder saure Sahne', 'Mehl für die Arbeitsfläche']
{'Quark', 'Obstsirup', 'Butter', 'Vanillezucker', 'Puderzucker', 'Sahne', 'Zucker', 'Mehl', 'Salz'}
i = 26
pred_i = y_pred_test[i] > 0.05
print(eval_tokenized[i])
print()
print(eval_ingredients[i])
print()
ingreds = [t.text for t, p in zip(eval_tokenized[i], pred_i) if p]
print(set(ingreds))
Spargel putzen und bissfest garen. Herausnehmen, abschrecken und warm stellen.Fisch mit Salz und Pfeffer würzen. Öl in einer Pfanne erhitzen und den Lachs darin 3-4 Min. je Seite braten. Butter schmelzen, Mandeln hinzufügen und leicht bräunen. Schale der Limette mit einem Zestenreißer abziehen, den Saft auspressen, beides in die Butter geben. Mit Salz und Pfeffer würzen.Spargel abtropfen lassen, mit Lachs anrichten und mit Mandelbutter beträufeln.Dazu passen Salzkartoffeln.
['500 g Spargel, weißer', '500 g Spargel, grüner', 'Salz und Pfeffer', '4 Scheibe/n Lachsfilet(s) (à ca. 200g)', '2 EL Öl', '100 g Butter', '30 g Mandel(n) in Blättchen', '1 Limette(n), unbehandelt']
{'Pfeffer', 'Öl', 'Fisch', 'Saft', 'Butter', 'Limette', 'Lachs', 'Spargel', 'Mandeln', 'Salz'}
This looks quite good! We build a quite strong model to identify ingredients in recipes. I hope you learned something and had some fun. You can try to improve the model by manual labeling or adding labels from a dictionary of ingredients.
