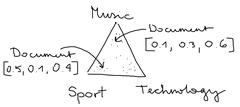
July 19, 2022How to calculate shapley values from scratch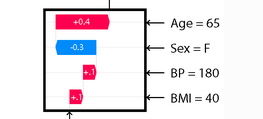 The shapley value is a popular and useful method to explain machine learning models. The shapley value of a feature is the average contribution of a feature value to the prediction. In this article I’ll show you how to compute shapley values from scratch.
Read more
The shapley value is a popular and useful method to explain machine learning models. The shapley value of a feature is the average contribution of a feature value to the prediction. In this article I’ll show you how to compute shapley values from scratch.
Read more
The shapley value is a popular and useful method to explain machine learning models. The shapley value of a feature is the average contribution of a feature value to the prediction. In this article I’ll show you how to compute shapley values from scratch.
Read more