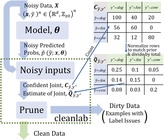
June 3, 2020Data validation for NLP applications with topic models In a recent article, we saw how to implement a basic validation pipeline for text data. Once a machine learning model has been deployed its behavior must be monitored. The predictive performance is expected to degrade over time as the environment changes.
Read more
In a recent article, we saw how to implement a basic validation pipeline for text data. Once a machine learning model has been deployed its behavior must be monitored. The predictive performance is expected to degrade over time as the environment changes.
Read more
In a recent article, we saw how to implement a basic validation pipeline for text data. Once a machine learning model has been deployed its behavior must be monitored. The predictive performance is expected to degrade over time as the environment changes.
Read more