In every machine learning project, the training data is the most valuable part of your system. In many real-world machine learning projects the largest gains in performance come from improving training data quality. Training data is often hard to aquire and since the data can be large, quality can be hard to check. In this article I introduce you to a method to find potentially errorously labeled examples in your training data. It’s called Confident Learning. We will see later how it works, but let’s look at the data set we’re gonna use.
import pandas as pd
import numpy as np
Load the dataset
From kaggle: https://www.kaggle.com/c/nlp-getting-started/data
df = pd.read_csv("data/train.csv")
df.head()
| id | keyword | location | text | target | |
|---|---|---|---|---|---|
| 0 | 1 | NaN | NaN | Our Deeds are the Reason of this #earthquake M... | 1 |
| 1 | 4 | NaN | NaN | Forest fire near La Ronge Sask. Canada | 1 |
| 2 | 5 | NaN | NaN | All residents asked to 'shelter in place' are ... | 1 |
| 3 | 6 | NaN | NaN | 13,000 people receive #wildfires evacuation or... | 1 |
| 4 | 7 | NaN | NaN | Just got sent this photo from Ruby #Alaska as ... | 1 |
Target denotes whether a tweet is about a real disaster (1) or not (0).
Let’s sample some tweets and have a look.
for tweet, label in df.sample(10)[["text", "target"]].values:
print(label, tweet)
0 Yet Brits are panicking about the UK http://t.co/HsDBGCIYrs
1 Japan Marks 70th Anniversary of Hiroshima Atomic Bombing http://t.co/jzgxwRgFQg
0 Hey there lonely girl
Did you have to tell your friends
About the way I got you screaming my name?
0 #Tigers Wonder how much the upheaval with team is affecting different players tonight?
0 'Since1970the 2 biggest depreciations in CAD:USD in yr b4federal election coincide w/landslide win for opposition' http://t.co/wgqKXmby3B
0 Eating takis then rubbing my eyes with my hands now my eyes are bleeding tears
0 The Dress Memes Have Officially Exploded On The Internet http://t.co/yG32yb2jDY
1 exporting food wont solve the problem. africans will end famine n poverty by SOLVING OUT OF CONTROL TRIBAL WARS. https://t.co/UttaNbigRx
0 Mane im not a Raiders Fan but they been in a drought. They need to go 10-6 lol
0 #BakeOffFriends #GBBO 'The one with the mudslide and the guy with the hat'
Build a probabilistc classifier
We use the Universal Sentence Encoder from tensorflow-hub to encode the tweets.
import tensorflow_hub as hub
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder-large/4")
X_train_embeddings = embed(df.text.values)
Now we fit a logistic regression on top of the encoded tweets.
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, f1_score
logistic_clf = LogisticRegression(n_jobs=-1, random_state=2020,
C=2, penalty="l1")
logistic_clf.fit(X_train_embeddings['outputs'][:6000,:],
df.target.values[:6000])
LogisticRegression(C=2, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='warn', n_jobs=-1, penalty='l1',
random_state=2020, solver='warn', tol=0.0001, verbose=0,
warm_start=False)
y_pred = logistic_clf.predict(X_train_embeddings['outputs'][6000:,:])
y_pred_proba = logistic_clf.predict_proba(X_train_embeddings['outputs'][6000:,:])
print("Accuracy: {:.1%}".format(accuracy_score(df.target.values[6000:], y_pred)))
print("F1: {:.1%}".format(f1_score(df.target.values[6000:], y_pred)))
Accuracy: 83.9%
F1: 82.0%
Estimate noisy labels
We use the Python package cleanlab which leverages confident learning to find label errors in datasets and for learning with noisy labels. Its called cleanlab because it CLEANs LABels.
cleanlab is:
- fast - Single-shot, non-iterative, parallelized algorithms
- robust - Provable generalization and risk minimimzation guarantees, including imperfect probability estimation.
- general - Works with any probablistic classifier
- unique - The only package for multiclass learning with noisy labels or finding label errors for any dataset / classifier.
How does confident learning work?
The central idea is that when the predicted probability of an example is greater than a per-class-threshold, we confidently count that example as actually belonging to that threshold’s class. The thresholds for each class are the average predicted probability of examples in that class.
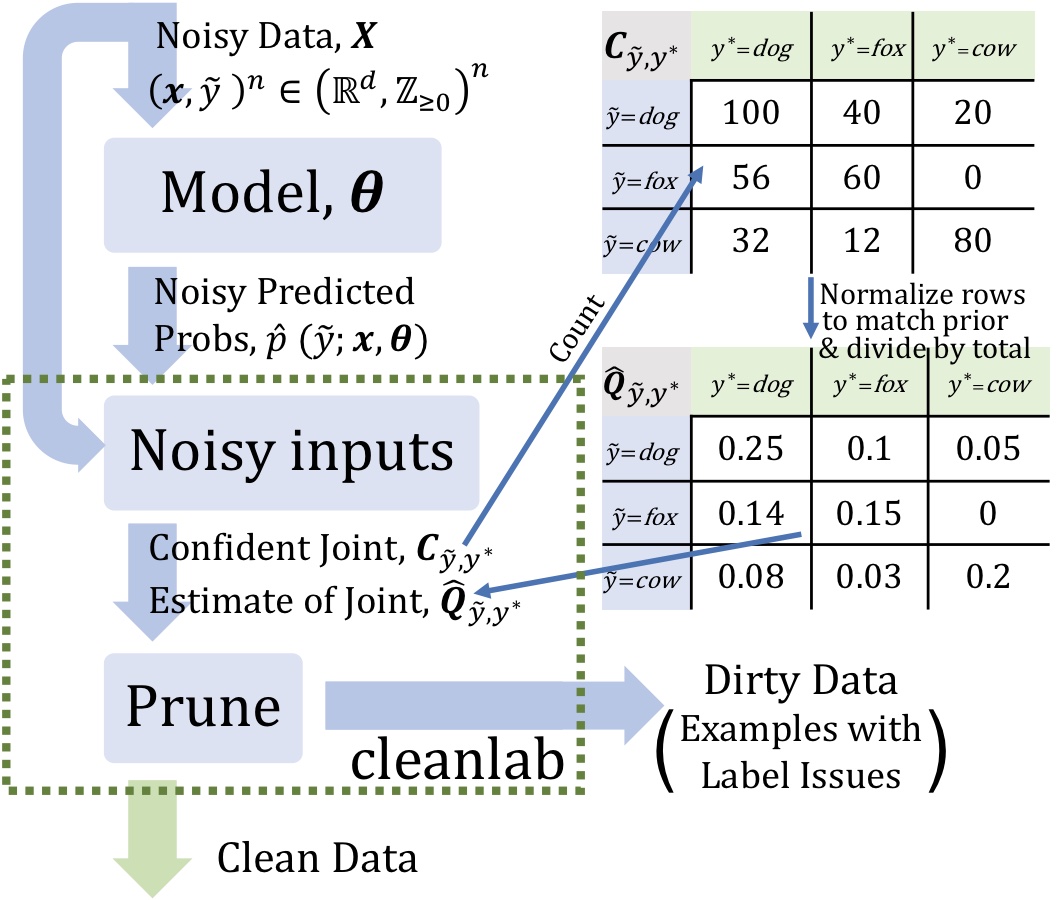
It works with any ML or deep learning model because there are only two inputs:
- a matrix of out-of-sample predicted probabilities for each example, for every class
- an array of noisy labels for each example
from cleanlab.pruning import get_noise_indices
ordered_label_errors = get_noise_indices(
s=df.target.values[6000:],
psx=y_pred_proba,
sorted_index_method='normalized_margin', # Orders label errors
)
print("We found {} label errors.".format(len(ordered_label_errors)))
We found 149 label errors.
Let’s look at the top-10 errorously labeled tweets.
error_df = df.loc[6000:].loc[6000+ordered_label_errors]
for idx, tweet, label in error_df[["id", "text", "target"]][:10].values:
print(idx, label, tweet)
8880 1 I get to smoke my shit in peace
9029 1 Keep shape your shoes ??#Amazon #foot #adjust #shape #shoe Mini Shoe Tree Stretcher Shaper Width Extender Adjustable http://t.co/8cPcz2xoHb
8721 1 Do you feel like you are sinking in low self-image? Take the quiz: http://t.co/bJoJVM0pjX http://t.co/wHOc7LHb5F
10823 1 @Kirafrog @mount_wario Did you get wrecked again?
9764 1 @onihimedesu the whole city is trapped! You can't leave the city! This was supposed to be a normal sports manga wit a love triangle (c)
8908 1 @Habbo bring back games from the past. Snowstorm. Tic tac toe. Battleships. Fast food. Matchwood.
8802 1 my dad said I look thinner than usual but really im over here like http://t.co/bnwyGx6luh
9040 1 @Stretcher @witter @Rexyy @Towel show me a picture of it
10680 1 Crawling in my skin
These wounds they will not hea
9912 1 @lucysforsale funny cause my dumb ass was the young one to get n trouble the most lol
Looks like we are getting a lot of tweets labeled falsely as disaster (1). By removing these labels from our training set, we get a more appropirate model for our usecase of identify to build a machine learning model that predicts which Tweets are about real disasters and which one’s aren’t.
Further reading
- Curtis G. Northcutt, Lu Jiang, Isaac L. Chuang: “Confident Learning: Estimating Uncertainty in Dataset Labels"
- https://l7.curtisnorthcutt.com/confident-learning
